协议语法逆向
1和2都使用了taint analysis,关注报文中的哪些偏移量上的内容被程序使用,以此来分割报文的字段,2对协议报文解析的更具体,比如它涉及到了1里边没有提到的Direction Fields。
1. Automatic Protocol Format Reverse Engineering through Context-Aware Monitored Execution
NDSS 2008
主要贡献:在未知协议双方程序源代码情况下,分析协议报文中都有哪些字段(通过监控程序运行时对协议报文偏移量的提取)
AutoFormat由两部分组成,Context-Aware Execution Monitor,Protocol Field Identifier。
Context-Aware Execution Monitor
标记接收到的消息中的每一个字节。在程序执行过程中,监控mov指令,和数学运算/逻辑运算指令,把接收到的消息传播到哪里都标注出来,即,对于一条指令,如果src是被标记的,标记它的dst,尤其是对于两个src operand都是被标记的,它的dst要被联合(union)标记。上述过程通过污点分析实现。
除了标记这些指令操作数,还要记录他们的运行栈,以及这些指令的偏移地址
Protocol Field Identifier
当读到带有标记的的内存地址时,记录形式如下$<o,c,s,l>$,o是被读的地方在整个报文的偏移量,c是它的内容,s是当时的函数调用栈,l是标记被引用的内存地址。
整个程序运行下来,会产生一个数组$log$,每个元素都是上面这个元组,$N$是这个$log$的长度
某些偏移量可能会被频繁引用,导致日志中出现连续的重复记录。AutoFormat首先对日志进行预处理,只保留连续重复记录中的第一个,以减少后续处理的复杂性。
有了这个log,接下来要构建一棵树$ftree$,用来表示这个报文。每一个叶节点都是一个$field$,对应着报文的某一个偏移量上的字段(文中叫做finest-grained fields,最小粒度字段),然后也有一些节点包含一群最小粒度字段(叫做hierarchical fields,比如http里,Request-Line就是一个层次字段,它包含GET、/path、HTTP/1.1这几个最小粒度字段)
其实就是整理成一个类似Wireshark的那种报文树形结构
以下是对$log$转变成$ftree$时的特殊处理:
关于如何创建新的节点:新创建的节点需要被链接到已存在的协议字段树中。会选择一个现有的节点作为新节点的父节点,这个选择的节点应该包含新节点的偏移量,但不包括其子节点。如果找不到这样的节点,新节点将作为根节点(ROOT)的子节点插入到树中。
有些叶节点可能具有过度细分的粒度,它们比实际的协议字段更小,可能是因为实现代码中包含的某些函数并不总是引用所有的字段偏移量。例如 $strcmp$、$strcasecmp$ 和 $strlen$ 等函数。
在log中,如果有连续两条记录$log[i]$和$log[i-1]$,他们的$log[i].o=log[i-1].o+1$,$log[i].s==log[i-1].s$,就把他们这两个偏移合并起来看成一个字段($p←UNION(p,q)$),如果不符合上述状况,后面的q就要创建成一个新的节点。
某些字段可能在不同的时间点被多次引用,导致它们在树中出现多次,成为冗余字段。AutoFormat通过删除冗余的节点来简化树结构,如果一个内部节点只有一个子节点,那么这个内部节点是冗余的,可以将其与子节点合并。这个过程会一直进行,直到没有更多的节点可以被删除。
报文中可能存在一些字段可能根本没有被引用。例如协议中可能设计时带有一些区分不同字段的”空格”。AutoFormat会识别报文中这些未被引用的字段,并将它们从树中移除或者合并到其他相关的字段中,以保持树的准确性和简洁性。
除了上述这些,文中还介绍了一个平行字段和顺序字段的识别(Identifying Parallel and Sequential Fields)
平行字段指的是报文中可以互换位置的字段,比如
1 | |
User-Agent、Accept、Host和Connection字段是平行的,因为它们可以以任何顺序出现。其余的有严格位置关系的就是顺序字段。如何识别平行字段?
对于父节点的每个子节点,会检查它们是否有相似的执行历史(execution history,文中就是这么叫的)。如果子节点的执行历史有共同的前缀(即它们在执行上下文序列中有相同的开始部分),则这些子节点被认为是并行的。
如果在两个已标记为并行的子节点之间存在未标记的子节点,那么这些未标记的子节点将被纳入并行字段,形成一个新的并行字段组。
Evaluation
文中做了两类实验
第一组实验(Known Protocols):这组实验涉及了六个已知网络协议的21个协议消息。这些协议包括:HTTP、SIP、DHCP、RIP、OSPF、CIFS/SMB
第二组实验(Unknown Protocol):第二组实验涉及了一个未知协议的消息,Slapper worm使用的恶意协议。
2. Polyglot: Automatic Extraction of Protocol Message Format using Dynamic Binary Analysis
CCS 2007
提出了一个叫做Polyglot的方法,用来分析协议报文格式,和上一篇论文一样,同样分为两个部分,十分相似:通过使用污点分析(Dynamic taint analysis)监视程序运行,观察程序对报文偏移量的使用,确定字段位置;针对这些偏移量,分析字段长度等信息。
在具体操作过程中,文章是按以下步骤进行描述的
Direction Fields
这个东西是第1篇文章没有提到的,那什么是Direction Fields?比如,报文中有一个字段,它的内容是另一个字段在这个报文中的长度。像这种没有实际意义,用来表示其他字段的位置信息(起始位置、字段长度等,pointer fields and counter fields)的字段,就叫Direction Fields。
如何检测Direction Fields?
- using arithmetic operations
当程序处理网络接收到的数据时,如果发现间接内存访问操作(即,访问的目的地地址是根据某些“污点”数据计算得出的),则这些操作可能是方向字段的使用。
如果一个指令访问了一个被标记为“污点”的内存位置,并且该目的地地址是由“污点”数据计算出来的(即,用于计算内存地址的基础或索引寄存器被标记为“污点”),那么这些连续的位置就会被标记为方向字段的一部分。
例如,如果一个指令访问了位置12-13,并且这些位置的地址是通过来自位置12-13的“污点”数据计算得出的,那么位置12就会被标记为方向字段的开始,位置18被标记为目标字段的结束。
这部分其实和上一篇论文中Context-Aware Execution Monitor这一部分的方法一模一样,只不过上个论文是“只要用到了污点,把他标记出来就可以了”。而这篇论文还要看看“这个污点是不是某个“Direction Fields”,是否用它来计算报文的偏移量。
- using a loop
前面一个说的是直接通过加法(起始地址+这个字段的size)来使用Direction Fields的,而还有另一种方法,即通过一个循环,从起始地址一个一个自增上去,来遍历这个”size“。
作者假设指针的增量是通过循环来实现的,直到达到某个结束条件,循环检测组件会从执行跟踪中提取循环,寻找包含向后跳转(即,跳转到较低指令指针的代码)的代码段,一旦发现循环,就会检查循环的停止条件是否由“污点”数据生成。如果是,那么这个循环就会被标记为“污点”循环。
- 如果长度是可变的
分为两种情况:Direction Fields在变长字段之前,和Direction Fields在变长字段之后。
大多数情况下,Direction Fields(也就是变长字段的长度)会在变长字段的前边,在识别出来一个Direction Fields之后,从它后边开始的这一系列字节被看作变长字节,比如某个Direction Fields代表长度为10,这个字段之后的10个字节就是那些变长字节(另外,如果存在一些没有被程序使用的字段,也会被算作变长字段的一部分)
当Direction Fields在变长字段之后,就不去特意识别它了,把变长字段和Direction Fields看作一个字段。
特殊情况还有如果使用了一些奇怪的字符集,这些Direction Fields里的数字就不是可以直接识别的
- 如果不是通过循环自增,而是通过自减
文中说,通过自减的方式遍历长度字段的情况还没有实现
原文:We believe the needed modifications to be small and plan to implement them in the near future.
Separator
报文中用来分割不同字段的标识符。这样的标识符一定是和报文中其余的字符全都不一样的字符
1 | |
比如这里的slash就是一种分隔符。在http协议里空格(0x20)和tab(0x9)都是字段内的分割符,并不只是文本协议有分隔符,二进制协议(比如Samba)也有。
如何检测Separator?
首先,分割符在程序解析报文时,通常会有比较字符的操作,这样程序才能定位分割符表示的界限。文章的方法会生成程序中所有涉及污点(tainted)数据的比较操作的摘要。这个摘要用于捕捉程序如何将接收到的数据字节与已知的分隔符值进行比较。(通过观察程序内cmp之类的指令)
然后,构建token表。会构建两个哈希表:tokens-at-position 表和 token-series 表。前一个表记录了每个缓冲区位置被比较过的token列表,而第二个表则记录了每个token被比较过的缓冲区位置列表。
扫描 token-series 表,寻找与连续缓冲区位置进行比较的token。通过设置最小系列长度为3,避免将偶然的比较误判为分隔符。这一步骤的输出是一系列可能的单字节分隔符及其使用的上下文(即它们出现的位置)。
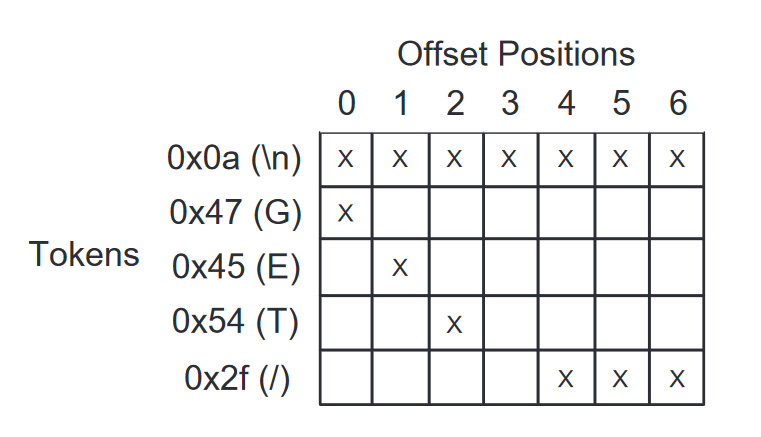
比如这个表,G、E、T这几个字符都在和\n这个字符比较。
有些分隔符可能由多个字节组成,如HTTP中的回车换行(0x0d0a)。为此尝试将之前阶段识别的单字节分隔符扩展为多字节分隔符。对于每个单字节分隔符的出现,检查其在应用数据中的前一个字节和后一个字节的值。如果相同的值总是出现在正在分析的单字节分隔符的前面(或后面),并且程序对该值执行了比较操作,那么将分隔符扩展以包含该值。
Keyword
关键字是协议规范中定义的固定值,比如标识协议版本、操作类型等。
如何提取关键字
与分隔符提取模块的第一阶段相似,涉及填充 tokens-at-position 和 token-sequences 表,这些表记录了程序中的比较操作。如果程序将接收到的某个字节序列与程序内部的某个值进行比较,并且这个值是协议定义的一部分,那么这个字节序列就是一个关键字。
3. Tupni: Automatic reverse engineering of input formats
2008年的CCS
文章提出了叫做Tupni的协议格式逆向分析的方法。这篇论文在2.1节提到了三个主要的识别目标:字段范围、字段序列、约束条件。前面两篇文章(借助动态污点分析)都侧重于逆向前两项(字段范围、字段序列),虽然也涉及到了一些约束条件方面的内容,但是显然不如这篇文章对其的侧重程度高。

在文章的整体流程图中,第一步Field Identification和第二步Identification of Record Sequences就是前文提到的用来检测字段范围和序列的程序,(对应文中3.3和3.4节),类型分类Identification of Record Types这一步对应3.5节,然后识别约束条件的方法对应3.6,作者说识别约束条件是贯穿整个流程的,没有作为一个单独的步骤画在流程图里。
文章的叙述方式为,从一个例子(Running Example,3.2)出发,在接下来的每一个小节中(3.3,3.4,3.5…)都先介绍了每一个环节的方法,然后结合这个例子,具体描述了报文数据是如何在程序中流动和加以分析的。

上图是用到的报文,下图是一段解析这个报文的程序。
Field Identification
首先,在3.3节中,文章介绍了如何使用动态分析确定有哪些字段。在动态污点分析的执行跟踪中,每个被读取的报文输入字节都会被标记为“受污染”(tainted),以表示它可能参与了后续的数据处理。
例如上图中,将input的偏移量offset上取内容,放入record_type,就是污点操作。
然后,Tupni分析执行跟踪中的每条指令及其操作数。当指令读取输入数据时,Tupni会检查操作数是否包含受污染的字节。而当Tupni识别出一系列连续的受污染字节时(这些字节在内存中是连续的),并且被同一个操作数所包含。这一系列连续的字节就构成了一个chunk。
例如上图中,程序通过一个循环,依靠自增变量i遍历的所有字节就构成了一个“chunk”。
最终的目标就在于,将这一系列的chunk,尽可能地一一映射到报文实际的字段上。
每个chunk被分配一个权重,该权重表示在执行跟踪中有多少条指令访问了这个chunk。权重有助于Tupni识别频繁访问的数据段,这些数据段更有可能是格式中的关键字段。
再有了“权重”这一属性之后,就可以开始解决将观察到的数据块(chunks)映射到输入字段的问题。文章把它归类为一个贪心算法,它可以被描述为一个加权最大k-集打包问题,即在多个块(可能相互重叠)的集合中找到最大数量的不相交块的子集,其中每个块都有一个与之关联的”权重“,表示有多少指令访问了这个块。Tupni的目标是找到一个一致的块子集,使得这个子集中的所有块都是不相交的,并且这些块的总权重最大。这样做的目的是为了将这些块映射到输入格式的实际字段上。以下是这个算法的操作。
- 首先,初始化一个空集,从权重最高的chunk开始,选择第一个chunk放入这个集合。这是因为它被访问的频率最高,因此最有可能是一个独立的字段。
- 按照权重从高到低的顺序,迭代地考虑每个chunk。对于每个chunk,Tupni检查它是否与已选择的chunk集合中的任何chunk重叠。如果一个chunk与已选择的任何chunk不重叠,则将其添加到子集中。
- 在添加新chunk的同时,更新子集,确保所有chunk都是不相交的。这一步是贪心算法的核心,它保证了所选择的块集合中没有重叠的chunk。
- 继续上述过程,直到所有chunk都被考虑过,并且不能向子集中添加更多的chunk而不产生重叠。
Identification of Record Sequences
而每个字段并不是完全独立存在的,它们可能涉及到输入数据中按照特定顺序或模式重复出现的记录集合。记录序列通常指的是输入格式中按照一定规则重复出现的一组字段,这些字段可以是简单的数据结构,也可能是复杂的嵌套结构。
Tupni通过分析程序的执行路径来识别记录序列(Record Sequences)。当程序处理输入数据时,通常会在循环结构中处理这些记录(copy到内存的变量中来)。
利用这一观察结果,通过识别循环的开始和结束,以及循环体内部访问的输入字段,来推断记录的边界和序列。这种方法的核心在于,程序在处理记录序列时往往会重复执行相同的代码块,因此通过分析循环的模式,可以揭示输入数据的重复结构。
在具体实现上,Tupni首先识别执行跟踪中的所有循环,并确定每个循环的入口点。然后,对于每个循环,Tupni分析循环体内部的指令,以确定哪些输入字段在循环的每次迭代中被访问。通过比较不同迭代中访问的字段,Tupni能够识别出记录的开始和结束位置,从而确定记录的边界。
为了提高识别的准确性,Tupni还采用了启发式方法来处理那些可能由于程序的不同执行路径而产生的复杂情况。例如,如果一个循环可能根据不同的条件执行不同的代码路径,Tupni会尝试识别所有可能的记录边界,并根据执行频率和数据依赖关系来确定最有可能的记录序列。 总的来说,Tupni的记录序列识别功能是通过结合动态分析和程序控制流分析来实现的。这种方法不仅能够识别简单的记录序列,还能够处理复杂的、嵌套的以及条件执行产生的记录结构。这使得Tupni在自动逆向工程领域具有强大的功能和广泛的应用前景。
Record Type Identification
“Record Type Identification”(记录类型识别)所指的“类型”是指输入格式中记录(record)的不同种类或分类。例如,在网络协议中,一个记录(Record)可能表示一个命令,另一个记录可能表示数据内容,而另一个记录可能表示会话控制信息等。在许多协议和文件格式中,记录可能有不同的类型,每种类型对应不同的结构和语义。Tupni通过分析处理记录的程序代码来识别记录类型。具体来说,Tupni观察循环结构中的指令序列,这些指令序列处理记录的不同部分。
通过比较不同记录的指令序列,Tupni可以推断出它们是否属于同一类型。如果两个记录由相同的函数或相似的代码路径处理,Tupni将它们归类为相同的记录类型。 在实现上,Tupni首先识别出所有处理记录的循环,并为每个循环创建一个指令序列的集合。然后,Tupni通过比较这些指令序列来识别记录类型。这一步骤涉及到复杂的启发式和模式匹配技术,以确保即使在面对高度优化的代码时也能准确地识别记录类型。
此外,Tupni还考虑了记录可能包含的嵌套结构。在这种情况下,Tupni不仅分析记录本身的处理代码,还递归地分析嵌套记录的处理代码。这种方法允许Tupni识别出复杂的、多层次的记录类型,这对于许多现代的协议和文件格式来说是必要的。 记录类型识别的挑战在于处理程序中的代码复用和多态性。在某些情况下,不同的记录可能通过同一个函数进行处理,但带有不同的参数或状态。Tupni通过跟踪这些参数和状态的变化来区分不同的记录类型。这种方法需要对程序的语义有深入的理解,包括函数调用、参数传递和控制流转移。 总的来说,Tupni的记录类型识别功能是通过深入分析程序的执行语义和控制流结构来实现的。这种方法能够准确地识别出输入格式中的不同记录类型,即使在面对复杂的程序逻辑和高度优化的代码时也能有效地工作。
Constraint Identification
涉及识别输入格式中字段之间存在的各种依赖关系和规则,例如,一个字段的值可能依赖于另一个或多个字段的值、字段可能需要符合特定的格式(如日期字段通常遵循“YYYY-MM-DD”的格式)、字段的值可能取决于特定的条件或逻辑判断,例如,只有当某个标志字段被设置时,某个字段才有效。
这些约束可能包括字段值的特定范围、字段之间的依赖关系,或者是根据某些条件必须满足的规则。识别这些约束对于自动逆向工程至关重要,因为它们有助于完整地理解输入格式的语义,并可以用于安全应用中,如检测异常输入或生成攻击签名。
Tupni通过动态数据分析来识别约束。在执行跟踪过程中,Tupni监视程序如何处理输入数据,特别关注那些涉及比较和计算的指令。例如,当程序计算校验和或执行边界检查时,Tupni会记录这些操作并推断出相关的约束条件。 在实现上,Tupni利用动态污点追踪技术来标记输入数据,并跟踪这些数据在程序中的流动。当程序执行比较操作(如等于、不等于、大于、小于等)或计算操作(如加法、乘法等)时,Tupni会分析这些操作的语义,以确定它们是否引入了对输入数据的约束。
此外,Tupni还考虑了跨消息的约束。例如,一个协议消息可能包含指向另一个消息的指针,或者一个消息的内容可能依赖于前一个消息的某些字段。Tupni通过分析程序的网络通信行为来识别这些跨消息的约束。 约束识别面临的挑战之一是处理程序中的条件逻辑。许多约束并不是总是生效,而是取决于特定的条件或输入数据的状态。Tupni通过分析程序的控制流和条件分支来处理这种情况,从而准确地识别出在不同情况下适用的约束。 另一个挑战是处理程序中的复杂计算和加密操作。这些操作可能会引入难以直接观察的约束。Tupni通过符号执行和抽象解释技术来推断这些复杂操作引入的约束。 总的来说,Tupni的约束识别功能是通过深入分析程序的执行语义和数据流来实现的。这种方法能够识别出输入格式中的各种约束,包括字段值的范围、字段间的依赖关系,以及跨消息的约束。这为自动逆向工程提供了强大的语义分析能力,并且可以用于提高安全应用的准确性和有效性。
4. ReFormat: Automatic Reverse Engineering of Encrypted Messages
2009年ESORICS
给定一个加密消息和一个能够解密并处理该消息的应用程序,ReFormat 系统的目的是输出消息的解密内容和格式。由于加密的输入消息首先会被解密,然后才会被处理,有必要区分这两个主要阶段,即消息解密和正常协议处理。 为了实现这一点,ReFormat 的方法基于:消息解密阶段和正常协议处理阶段的指令分布显著不同。现有的加密算法(如 Triple-DES、AES 和 RC4)通常包含大量的算术和位操作,并且这些操作会应用于原始消息的所有字节。相比之下,在正常协议处理阶段,观察到的算术和位指令会显著减少。
ReFormat 系统实现目标的关键步骤如下(如图所示):

执行监控(Execution Monitor):首先监控应用程序的执行并收集执行跟踪,记录应用程序如何解密和处理输入消息。
ReFormat 通过拦截用于读写文件描述符和/或网络套接字的系统调用来运行污点分析技术,标记输入消息,并跟踪访问被标记内存空间的指令。通过动态地对程序执行进行插桩,可以正确地传播污点信息,并收集操作被标记数据的指令的跟踪。收集的跟踪仅包含操作被标记数据的指令,而非所有执行的指令。
阶段分析器(Phase Profiler):然后分析执行跟踪以识别两个执行阶段:消息解密和正常协议处理。
在收集到执行跟踪后,阶段分析器将其划分为不同的执行阶段。应用程序通常会在四个阶段处理加密的输入消息并用加密的消息做出响应:(1) 解密输入消息,(2) 处理已解密的消息,(3) 生成输出消息,(4) 加密输出消息。ReFormat 的目标是识别第一阶段和第二阶段之间的边界。
数据生命周期分析器(Data Lifetime Analyzer):执行数据生命周期分析以定位包含解密消息的缓冲区。
确定消息解密阶段和正常协议处理阶段后,下一步是定位包含解密消息的内存缓冲区。基本思想是识别在消息解密阶段写入并在正常协议处理阶段读取的缓冲区。通过分析内存缓冲区的生命周期来识别这些缓冲区。
格式分析器(Format Analyzer):最后,对上一步骤中定位的缓冲区进行动态数据流分析,以揭示解密消息的格式。
由于最后一个步骤已经在先前的研究中广泛研究过,本文主要关注前三个步骤。在原型中,作者使用 AutoFormat 作为格式分析器,但其他系统如 Polyglot、Wondracek 等人的系统和 Tupni 也应该可以用于相同目的。
接下来将详细介绍每一部分是如何具体实现的
Execution Monitor
在文中,作者提到ReFormat用以下几种方法来监控程序的运行:
系统调用拦截:ReFormat 通过拦截系统调用来监控程序对文件描述符和网络套接字的读写操作。这些系统调用通常与消息的接收和发送有关。
动态插桩:为了能够监控程序的执行,ReFormat 使用动态插桩技术。这意味着它能够在程序运行时,实时地插入额外的代码来收集执行信息。
污点分析:利用污点分析技术来标记输入消息,并跟踪任何访问这些被标记数据的指令。当程序读取输入消息时,ReFormat 将消息标记为“污点”,并在程序执行过程中传播这些污点信息。
指令跟踪:特别关注那些操作被标记数据的指令。它记录下这些指令的地址和当前的调用栈信息。调用栈信息对于确定程序执行的上下文非常重要。
内存和寄存器监控:监控程序对内存和寄存器的访问,确保所有与输入消息相关的操作都被记录下来。
数据流分析:通过分析收集到的指令跟踪信息,能够理解数据在程序中的流动情况
通过 Execution Monitor,ReFormat 能够为后续的分析阶段提供丰富的数据,这些数据是自动逆向工程加密消息格式的关键。这种方法的成功实施为自动化安全分析工具的发展提供了新的可能性,尤其是在处理加密流量时。
Phase Monitor
Phase Profiler 的核心任务是识别执行跟踪中的两个主要阶段:消息解密和正常协议处理,主要基于程序的运算指令的密度来区分,运算指令特别密集的地方被认为是解密消息的部分。
Phase Profiler 首先使用累计百分比(文中原文叫做the cumulative percentage)的方法来缩小搜索范围,寻找从消息解密阶段过渡到正常协议处理阶段的点。这个”累计百分比“指的是:对于执行跟踪中的每条指令,ReFormat 计算到该指令为止所有算术和位操作指令的累计百分比。这是通过将算术和位操作指令的数量除以总指令数量并乘以 100 得到的。
在消息解密阶段,由于涉及到大量的算术和位操作,因此累计百分比会达到一个峰值。而在正常协议处理阶段,由于这类操作显著减少,累计百分比会下降到一个谷值。Phase Profiler 寻找这个峰值和谷值,以确定过渡点。
在确定了累计百分比的峰值和谷值之后,Phase Profiler 进一步分析这两个点之间的函数片段。函数片段是指属于同一函数并且在相同的上下文中执行的连续指令集合。为了确定具体的过渡点,Phase Profiler 计算这两个点之间每个函数片段中算术和位操作指令的百分比,并与预设的阈值进行比较。如果某个函数片段的百分比高于阈值,则认为它属于消息解密阶段;如果低于阈值,则认为它属于正常协议处理阶段。
最后一个算术和位操作指令百分比高于阈值的函数片段作为过渡函数。这个函数中的最后一个执行指令被认定为从消息解密阶段到正常协议处理阶段的过渡点。
Data Lifetime Analyzer
Data Lifetime Analyzer 的目标是识别在程序执行过程中,哪些内存缓冲区包含了从加密消息解密得到的数据。
首先定义了内存缓冲区的活性状态。如果它是为全局变量预分配的,或者在堆或栈上被新分配出来,那这个缓冲区被认为处于活性状态。当一个活性缓冲区被从堆栈上释放或被访问(读或写操作)时,它就变为无效。
在消息解密阶段,系统会搜索所有被写入的缓冲区,并记录这些缓冲区的集合,称为写入集,write set
当程序进入正常协议处理阶段,系统会搜索所有首次被读取的活性缓冲区,并记录这些缓冲区的集合,称为读取集,read set
通过寻找写入集和读取集的交集来确定包含解密消息的缓冲区。这个交集中应该包含那些在消息解密阶段被写入,在正常协议处理阶段被读取的缓冲区。
如果交集中存在多个缓冲区,系统将根据首次读取操作的时间顺序对它们进行排序。然后,这些缓冲区被视为一个虚拟的单一缓冲区,包含了整个解密消息。
也就是说,这个阶段的目的是得到一个缓冲区,近似地去替代明文报文,然后进行格式分析
为了说明这个方法的可行性,在3.4作者通过实验进行验证。他们使用 ReFormat 原型对几种不同的协议进行了测试,包括 HTTPS、IRC 和 MIME,以及一个未知的恶意软件协议。在所有测试案例中,ReFormat 都能准确识别包含解密消息的运行时缓冲区。
Format Analyzer
如前文所述,文章对这部分内容不做介绍,直接引用相关文献介绍中的那几篇文章的方法,对上述缓冲区进行格式解析。