Deep Exploit 程序分析
Deep Exploit 程序分析
一. 使用方法
下载仓库代码,安装运行环境
1 | |
但实际安装时是手动逐个安装的,比如matplotlib==3.0.3可能因为版本太旧了装不上,只能用新的版本。
按照官方文档,使用时需要两台机器,一台远程服务器运行metasploit,一台主机执行这个仓库的DeepExploit.py,远程服务器通过RPC(远程过程调用)来运行 DeepExploit。但实际使用时把两端都放在一台主机上也是可以的(以下过程都是基于此)。
在config.ini中,可以配置运行metasploit主机的RPC的用户名和密码
1 | |
服务端启动metasploit框架,监听指定端口
1 | |
客户端运行DeepExploit建立连接
1 | |
客户端参数
-t 代表攻击的目标主机
-m 有两种选项,train或test,后面会具体介绍
-p 指定端口
-s 指定要测试的服务或应用程序,可供选择的服务见config.ini,通常与-p一同使用
二. 各文件/代码作用
### 0. config.ini包含程序各个部分的参数配置
[Common] : 程序要远程连接到运行metasploit的服务器端,common部分包含服务器端的ip、端口、用户名、密码;此外,还包含程序内动态生成的训练数据(train_data)的存储位置
[Utility]:util.py用到的一些参数,不重要
[State] : 包含 能够识别的目标主机操作系统列表,可供选择的服务/程序列表
1 | |
[A3C] : 训练时超参数
[Nmap] : 调用nmap的命令行指令
[Report] : 生成报告的配置信息,比如日期
[VersionChecker][VersionCheckerML][ContentExplorer]:这三者是分析目标主机端口运行的程序时用到的配置参数
[Spider] : 爬虫的配置信息,包括爬虫结果的存储路径、爬虫时的timeout和并发请求数量等
1. util.py
只包含一个类Utility,功能包括:
格式化输出(print_message、print_exception)
网页爬虫(parse_url、run_spider)在Metasploit.get_target_info中被使用
字符串处理(delete_ctrl_char、transform_date_object、transform_date_string)
发送http请求(send_request)
检查目标端口是否是http或https协议(check_web_port)在Metasploit.get_target_info中被使用
2. CreateReport.py
只包含一个类CreateReport,只有一个函数create_report,用于生成报告,不重要
3. Spider.py
包含了网络爬虫的脚本,这个py文件会在Metasploit.get_target_info中,通过scrapy 命令进行调用
1 | |
代码的功能是从一个指定的起始URL开始,递归地爬取网页,并从中提取链接和脚本资源
详细用法见 Metasploit.get_target_info
4. modules文件夹
其中有ContentExplorer.py,NaiveBayes.py,VersionChecker.py,VersionCheckerML.py 四个程序
会在后面用到的时候一并分析,不单独介绍
均是在Metasploit.get_target_info 用到的,功能是如何用基于指纹/基于机器学习的方法对目标主机上运行的服务进行识别。
5. DeepExploit.py
包含程序的核心代码,执行时也是从这个py文件启动
class Msgrpc
这个类定义了许多与metasploit服务器进行交互的 基本操作,包括如何登陆、如何发送指令、如何维持与服务器的会话状态。
__init__
从 config.ini 读取用户名和密码,用来和服务器立端的metasploit建连接,metasploit的RPC连接实现其实就是一个http/https协议
1 | |
调用metasploit的 RPC API,用来指导服务器端的metasploit执行什么命令,有两个参数,meth、origin_option
Msgrpc这个类中,后面的函数几乎都是在用这个call函数通过不同的命令来与metasploit服务器进行交互,例如
1 | |
这个例子通过console.create命令创建了一个远程的cmd,call函数会返回cmd的id,后面只需要使用这个id编号就可以在服务器上执行命令了,例如 读取命令行的输出
1 | |
或者指定执行的命令
1 | |
set_api_option
在发送请求到Metasploit 服务器之前,会根据需要调用的API方法(meth)准备相应的选项参数(option)
比如在已经验证过用户名密码之后,每次交互都要把用来验证身份的token加到选项里(详见Msgrpc.log_in)
send_request
这个函数就是call函数发送http报文的具体实现,将抽象的 ”指令“ 转化为具体的 ”http报文“ 发送给metasploit服务器
通过发送用户名和密码登录metasploit服务器
1 | |
登陆成功后会拿到一个token,后续交互使用这个token维持身份认证
keep_alive
保持会话存活,具体做法是发送一个获取版本的指令
1 | |
get_console
向服务器申请一个命令行,详见Msgrpc.call
send_command
对指定的命令行发送命令,并获取返回结果,详见Msgrpc.call
可以通过参数中的Visualization参数控制是否输出命令执行结果
1 | |
在Metasploit框架中,模块是指具有特定功能的插件,它们可以执行各种安全测试任务。每个模块都封装了测试或攻击某个特定目标所需的逻辑和数据。Metasploit框架中的模块类型主要包括:
- 漏洞利用(Exploits):这些模块利用目标软件中的安全漏洞来获取对目标系统的访问权限。它们可以执行远程代码执行、权限提升、拒绝服务攻击等。
- 辅助(Auxiliary):辅助模块用于支持性任务,如端口扫描、服务识别、漏洞检测等。它们不直接攻击目标,而是为攻击提供信息。
- 后期利用(Post):后期利用模块在成功利用漏洞后执行,用于进一步操作,如提升权限、收集敏感数据、清理痕迹等。
- 载荷(Payloads):当一个漏洞被成功利用时,载荷是被上传到目标系统上执行的代码。它通常用于在目标机器上建立一个会话,如反向shell。
- 编码器(Encoders):编码器模块用于对载荷进行编码或加密,以规避目标系统的安全机制,如入侵检测系统(IDS)或防病毒软件。
- Nops:NOP滑梯是一系列无操作(NOP)指令的序列,它们可以被用来覆盖缓冲区溢出攻击中的多余空间。
为了方便理解,这个call函数对应的真实msfconsonle指令是show,比如show exploits就会列出所有exploits模块下的漏洞,以下是输出结果中的一部分
1 | |
get_module_info
1 | |
针对get_module_list得到的列表中的某一项,获取其信息,例如
1 | |
get_compatible_payload_list
发送一个模块的名字,返回这个模块有哪些payloads
1 | |
get_target_compatible_payload_list
类似上一个函数
1 | |
两者的区别:
- compatible_payloads:
- 此方法返回与特定漏洞利用模块兼容的所有载荷列表。
- 它不针对特定的目标或目标编号,而是提供该模块普遍兼容的载荷概览。
- target_compatible_payloads:
- 此方法返回与特定漏洞利用模块以及特定目标编号(target index)兼容的载荷列表。
- 它更具体,因为它考虑了模块支持的目标中特定的一个,并返回适合该特定目标的载荷。
简而言之,
compatible_payloads提供了一个广泛的兼容载荷列表,而target_compatible_payloads则根据指定的目标提供了一个更加定制化的兼容载荷列表。
get_module_options
获取指定的模块的选项
1 | |
比如使用exploit模块里的某个漏洞,使用时要指明攻击的目标主机的ip,这个ip就是options里的一项。
execute_module
选定某个模块功能(比如指定exploit模块里的某个漏洞利用功能)进行执行
1 | |
比如一个执行例子:
1 | |
get_job_list
获取metasploit有哪些任务正在执行,返回一个job_id的列表
1 | |
get_job_info
指定某个job_id,获取信息
1 | |
实际上这个函数在程序里根本没有被调用过,也不用了解info都有什么了
stop_job
停止某个任务
1 | |
get_session_list
在metasploit里,session指的是在漏洞利用成功之后,与被攻击系统之间建立的交互式连接或会话。
1 | |
stop_session
停止某个session
1 | |
stop_meterpreter_session
session是建立一个连接,通过shell执行发送过去的命令,Meterpreter可以看作一个特殊的shell
1 | |
Meterpreter和普通shell的区别
Meterpreter 比系统 shell 更加灵活,功能更加丰富,例如监控主机,监控键盘,开启摄像头,麦克风,还可
以灵活的获取你的操作系统信息。
高级,动态,可扩展的 payload,一站式后攻击 payload;
基于 meterpreter 上下文利用更多漏洞发起攻击;
后渗透测试阶段一站式操作界面;
完全基于内存的 DLL 注入式 payload(不写硬盘)
注入合法系统进程并建立 stager
基于 stager 上传和预加载 DLL 进行扩展模块的注入(客户端 API)
基于 stager 建立的 socket 连接建立加密的 TLS/1.0 通信隧道;
利用 TLS 隧道进一步加载后续扩展模块(避免网络取证
execute_shell
指定某个session,在已攻陷的主机上执行指定shell命令
1 | |
get_shell_result
获取执行的shell命令的结果(实际程序中没用到这个函数)
1 | |
execute_meterpreter
和execute_shell一样,针对meterpreter类型session的实现
1 | |
execute_meterpreter_run_single
(实际程序中没用到这个函数)
1 | |
get_meterpreter_result
和execute_shell一样,针对meterpreter类型session的实现
1 | |
upgrade_shell_session
将普通的shell升级为meterpreter
1 | |
logout
termination
结束与metasploit服务器的通讯
class Metasploit
在Msgrpc类中,定义了许多基本的与服务器交互的操作,在Metasploit类中,介绍了在Deep Exploit中,是如何使用这些基本操作的,即对这些基本操作的更高层次的封装
除了下边介绍的函数,类中还有很多不重要或特别简单的函数,用到的时候会一句话带过
__init__
这个构造函数的功能按执行顺序列举如下:
- 读取各种配置参数(从config.ini),此处略
- 创建一个
Msgrpc对象
1 | |
- 登录并从Metasploit获取一个命令行
1 | |
get_exploit_tree
exploit tree是一个数据结构,存储 “漏洞-操作系统-这个漏洞针对不同操作系统的payload” 的对应关系
在这个函数中,首先会在data目录下是否有exploit_tree.json文件,如果没有则从服务器获取exploit tree,否则就从这个文件读取
从本地读取的代码很简单:
1 | |
如果本地没有这个文件,就需要向服务器查询。查询的过程是,首先使用use命令,指定某个漏洞,然后使用show targets,列出受该漏洞影响的所有系统类型
1 | |
比如show targets的一个例子如下图所示:
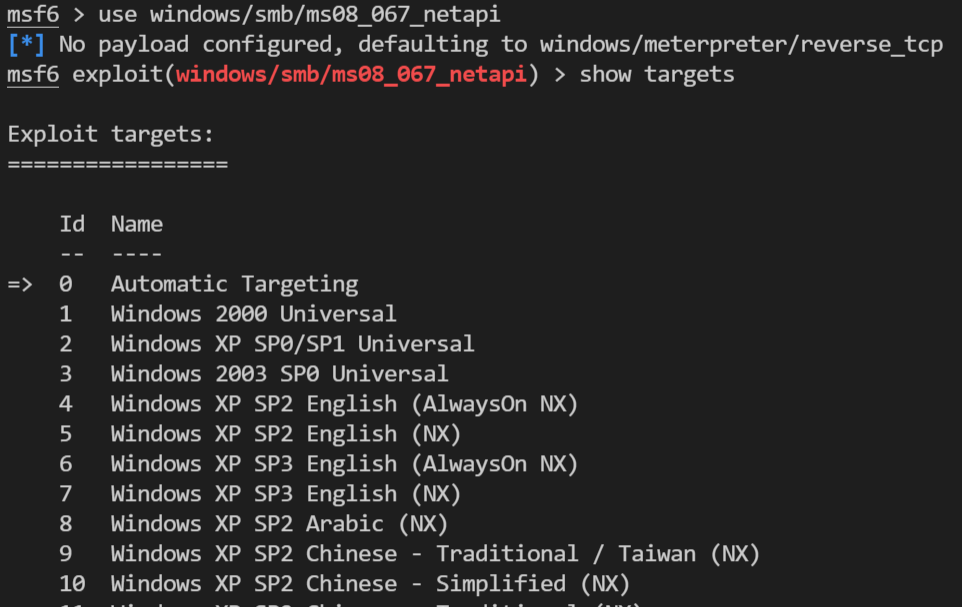
接下来,根据每个target,获取对应的payload (参数里的exploit是一个具体的漏洞,target是一个编号)
1 | |
也就是从这里开始,才看出来,这个函数为什么叫做tree,这里的temp_tree就是一颗每个叶节点都是针对不同平台的payload的树。
接下来获取每个漏洞的options,即这个漏洞利用前需要做的配置
1 | |
以下是漏洞的options的一个例子,会显示哪些参数是必须手动设置的
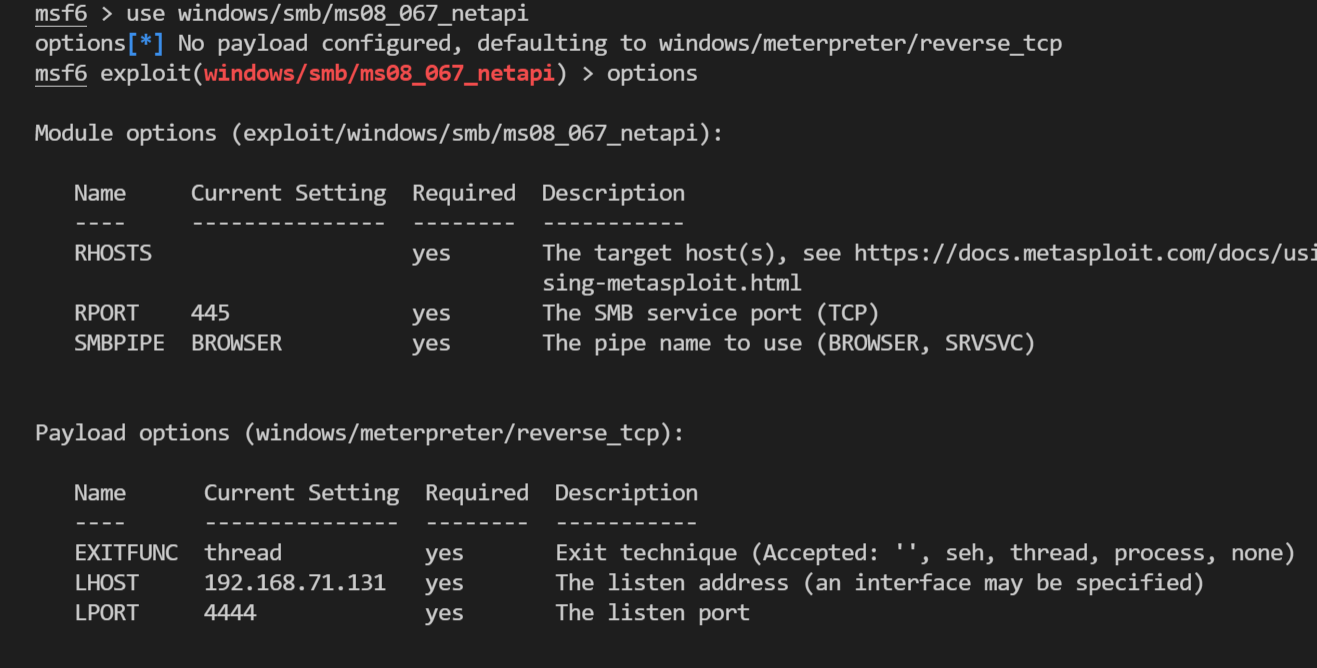
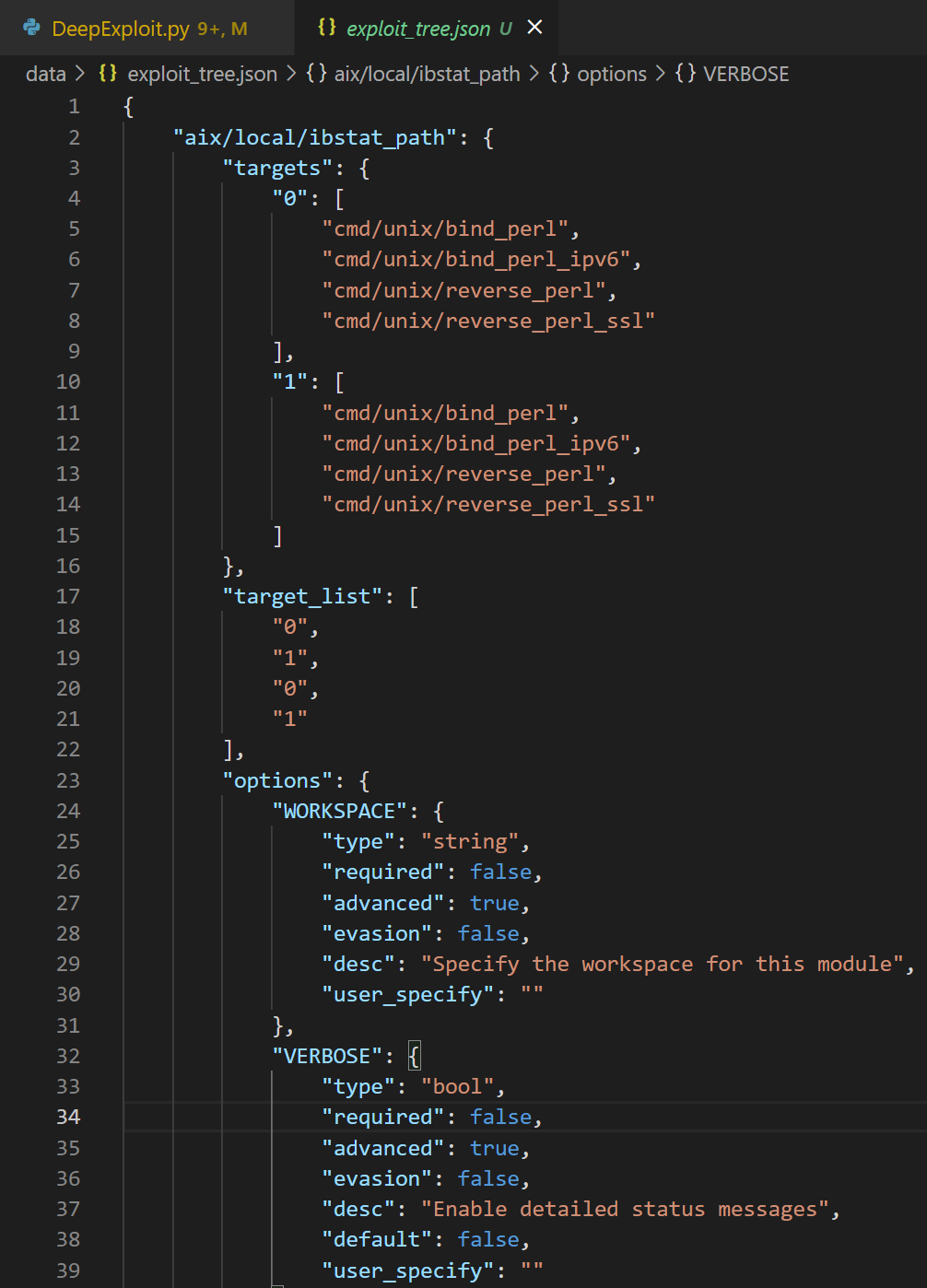
然后这些options也会组织成一个字典的形式,结合前面的payload的树,最终合并成一个树,也就是exploit_tree,会把它存储在data目录下的exploit_tree.json中
1 | |
这个文件的示例如下
get_target_info
在不指定端口的情况下,获取目标主机所有端口上运行服务的详细信息(比如版本)
代码结构同样是如果本地有这个主机的记录就从本地读取,没有就让Metasploit服务器扫描分析
1 | |
如果本地没有记录,则会开始分析
首先会检查一下开放的这些端口里有没有http或https协议:
1 | |
对检测到的http或https协议,通过爬虫获取网站的内容(递归扫描资源路径)
1 | |
这个run_spider调用scrapy命令,以下是其内部的实现:
1 | |
scrapy命令会在crawl_result文件夹下存储这个扫描结果的输出,run_spider以列表的形式返回这些网站内容。(因为网站可能有很多不同的资源路径)
接下来就会分析服务的版本信息,使用了两种不同的方法,一种是基于签名的识别,一种是基于机器学习的识别
1 | |
基于签名的识别比较简单,在signature/signature_product.txt文件中,会存有一系列的正则表达式
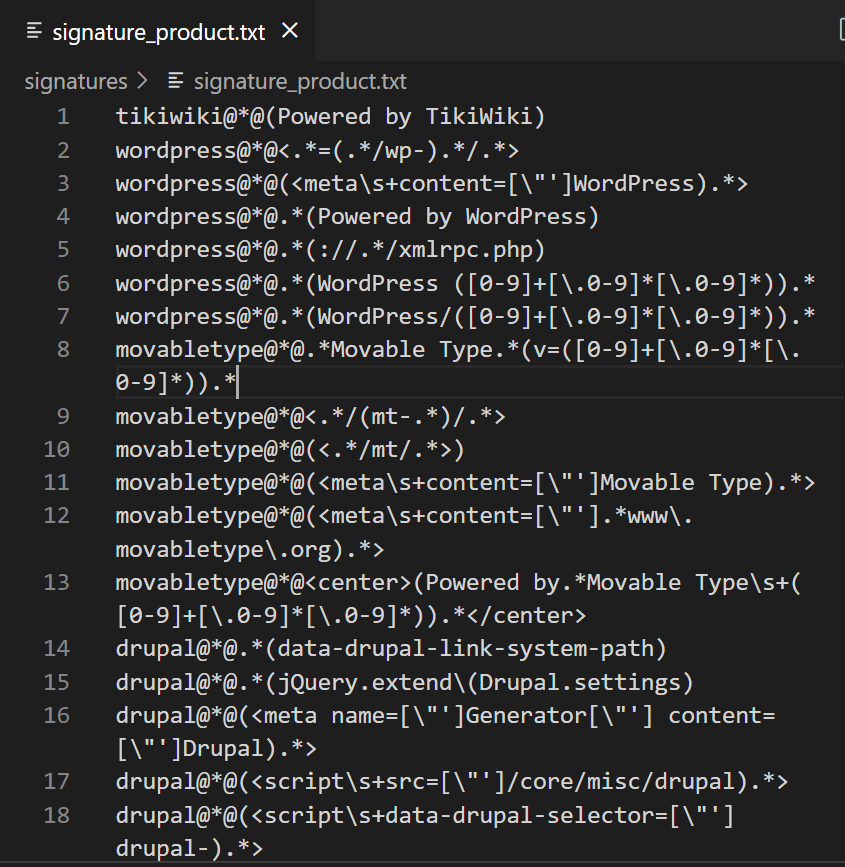
version_checker.get_product_name中,会使用这些正则表达式是用来匹配写在http响应的header和body中,程序及版本信息
1 | |
另一种是基于Naive Bayes的识别,既然是基于朴素贝叶斯的算法,那就一定要有一些数据,来计算先验概率,对于这一点,version_checkerML.get_product_name就使用了modules/train_data/train_cms.txt中的内容进行了训练。(这里的train和命令行参数指定的无关,也就是无论是train模式还是test模式,这里都需要训练一个先验概率出来,而且是每次执行都要训练一遍train_cms.txt的内容)
1 | |
其实,config.ini中会指定一个要预测的product category,比如CMS、比如OS、比如Middleware。config.ini 默认指定的是CMS,并且train_data文件夹下只提供了cms的训练数据,而且train_cms.txt也只有六行训练数据,真的要实际使用Deep Exploit需要补充数据和类别。
在train函数中,调用了module\NaiveBayes.py。训练之后就用这个分类器预测一下目标服务,给出标签。
这是train_cms.txt原本的内容,@分割之后,最后一列是训练数据,第一列是标签
1 | |
除了
version_checker.get_product_name和version_checkerML.get_product_name,代码中还有一个叫做基于“default content”的识别方法content_explorer,这个方法和version checker 的区别在于,version checker 只是用 http响应的header和body进行搜索,content explorer 使用完整的http报文,但还是基于签名的识别
以上是获取产品名及其版本的步骤,最终要得到的是如下形式
1 | |
protocol 是之前nmap扫描结果里的协议版本,比如tcp,target_path是这个网站上有哪些资源路径,exploit则是通过在Metasploit服务器上搜索这个程序的漏洞的结果
1 | |
针对每一个端口的temp_tree合起来就是最终的返回结果就是target_tree
get_target_info_indicate
功能和get_target_info 一致,只不过因为指定了目标端口和服务名称,不会再扫描目标主机,返回结果和上一个函数相比只是少了 target_path
1 | |
prod_name是直接从命令行参数copy过来的,version 也不会检测,直接被赋值成0.0,protocol直接被赋值成tcp,exploit部分依旧和前一个函数一模一样。
extract_osmatch_module
在get_target_info 中被调用,用来匹配漏洞是否适配于某个操作系统版本
execute_nmap
nmap是由服务器端执行的,通过console.write命令,让Metasploit执行一个控制台命令,命令是由config.ini中写好的nmap指令和参数。
1 | |
端口扫描的结果会以xml的格式保存,(这个xml文件会保存在服务器端,但是在测试的时候服务器端和客户端用的是同一主机)
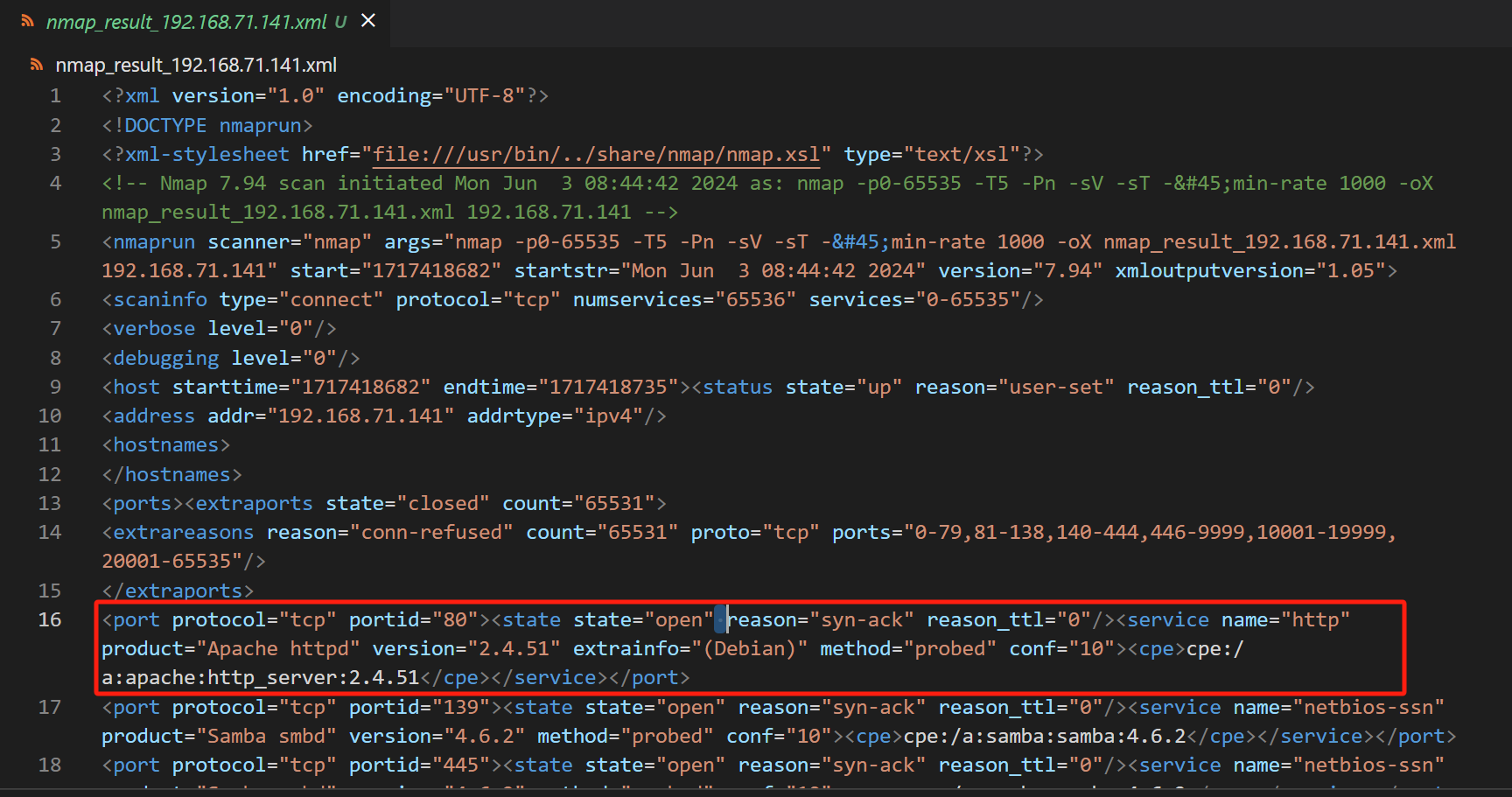
这个函数只是让服务器端进行了端口扫描,将结果传回客户端是由下一个函数get_port_list执行的。
get_port_list
这个函数会在程序执行 execute_nmap 之后运行,函数参数中,会传入nmap扫描之后,保存到本地的文件路径。并且会在data目录下检索是否之前获取过这个ip的端口列表,如果之前有记录,则直接读取结果。
1 | |
如果之前没有,则会向服务器进行查询(也就是读取execute_nmap的执行结果文件)
通过发送一个cat命令,将xml文件内容读取发送回客户端
1 | |
返回给客户端的结果包含:端口号、协议、程序/服务名、版本等,还有对目标主机操作系统的识别结果
然后存入本地data/target_info_<ip>.json中
get_exploit_list
首先会在data目录下检查是否有exploit_list.csv文件,没有则向服务器查询,有则直接读取
1 | |
如果是从服务器请求,是通过 Msgrpc.get_module_list 函数来获取的,遍历exploit 模块下的所有漏洞
1 | |
将获取到的漏洞列表存入exploit_list.csv中
1 | |
在本地测试之后,生成csv的内容如下
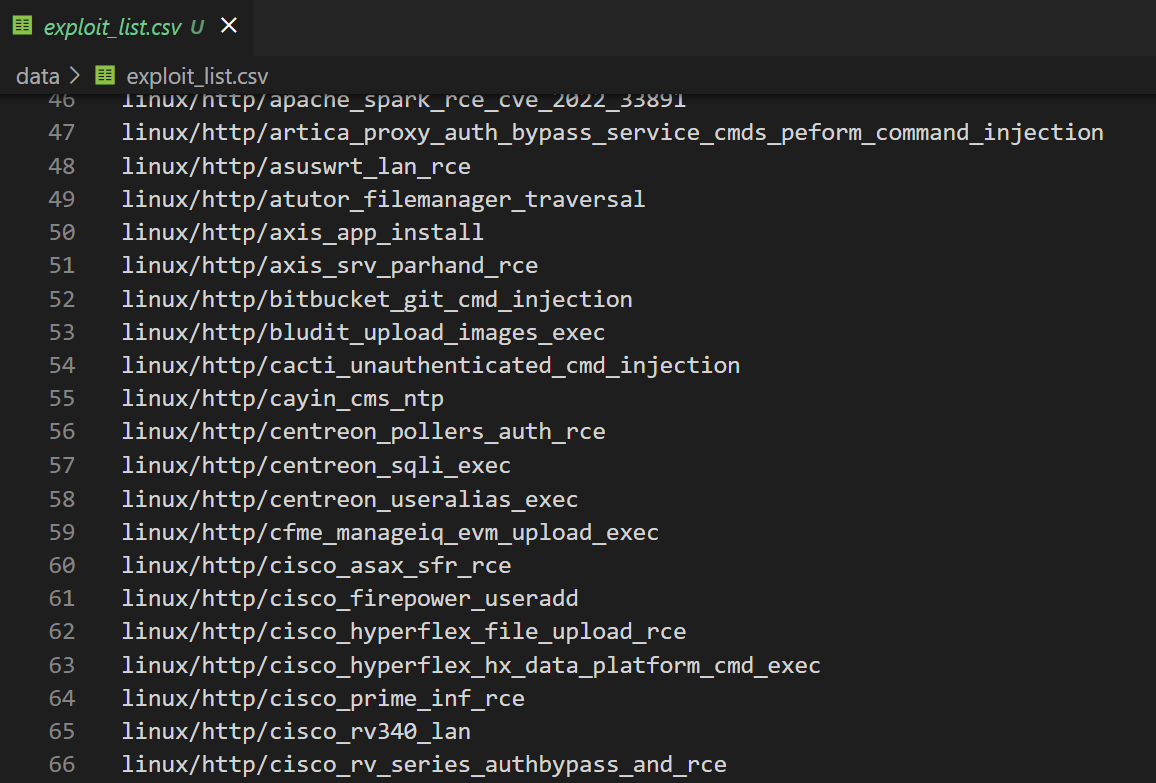
可以看到它其实并不是逗号分隔符文件
get_payload_list
代码形式和 前一个 get_exploit_list 一致,只不过是把获取漏洞改成获取payload,同样存到一个csv(payload_list.csv)中
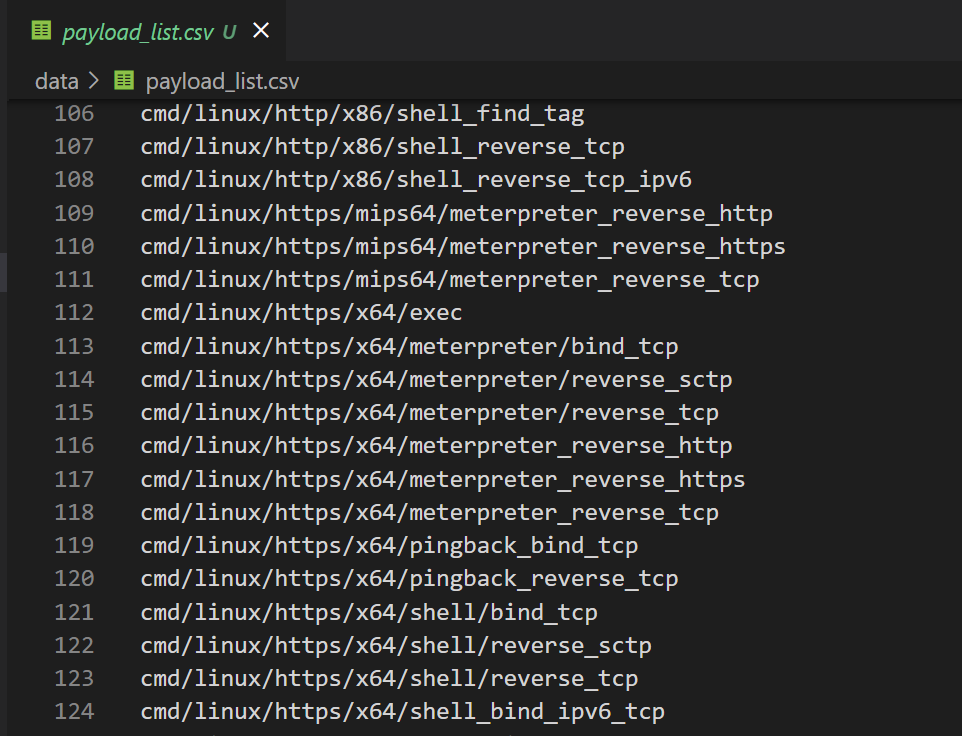
execute_exploit
这个函数是在测试或训练时,运行那些在Agent.act中给出的根据概率排好序的payload,即测试这些神经网络给出的payload能否正确运行。
execute_post_exploit
execute_post_list会在execute_exploit测试之后,对那些成功执行了的payload(即拿到了Metasploit的session_id),在其上运行arp命令,探测它们所在的内部网络中的其他主机信息(即get_internal_ip函数)
然后set_pivoting会通过 run get_local_subnets 命令 获得子网信息,通过run autoroute命令 将主机作为跳板
1 | |
execute_post_exploit会返回这些内网IP,而且这个函数只会在test模式下被调用,后面会对子网内的设备进行渗透测试
class ParameterServer
##### **`_build_model`**定义了网络结构
1 | |
网络很简单,前四层就是普通的全连接,out_actions是强化学习中,在给定状态下采取每个可能动作的概率,out_value是对应的奖励值
但是最终模型要copy到LocalBrain中,进行训练或测试(见LocalBrain)
这三者放在一起分析,顾名思义,就是强化学习中,用来执行操作的智能体(Agent)、帮智能体决策的大脑(LocalBrain)、反馈奖励的外部环境(Environment)
##### **`Environment.run`**首先介绍 test部分
由WorkerThread.run直接调用,在这个环境(Environment)中,第一步就是创建一个Agent,这个Agent又有自己的大脑(LocalBrain),模型参数会传入大脑中。
1 | |
接下来要遍历target_tree中的漏洞列表
1 | |
把漏洞交给Agent去探索利用方法,即agent.act函数,提供的信息有状态(s)当前可以执行的payload(available_actions)和 贪婪策略(eps_steps)(见Agent.act)
这里的状态s包括 操作系统类型、服务名、版本、可利用的漏洞、漏洞能够影响的操作系统版本,这也就是后面神经网络的输入
这里的eps_steps指的是 训练周期数 * 贪婪率。一开始是采取随机的执行策略,当达到这个eps_step的步数时,就开始一直尝试最优的策略
1 | |
在test中,根据Agent.act返回的已经根据概率排好序的payload,逐个进行测试,测试的过程分两步execute_exploit 和 execute_post_exploit
前者会测试这些payload能不能正确运行,后者会对成功攻击的主机作为跳板,探测其内网主机ip(见Metasploit.execute_post_exploit)
这个第二步在train模式下是没有的
1 | |
那如何利用跳板对内网发起攻击?
首先通过metasploit的辅助模块中socks4a做了一个代理,然后通过deep_run对内网主机进行分析
1 | |
deep_run依旧是通过nmap获取主机端口,建立exploit_tree和target_tree,然后反过来条用run函数,形成了一个递归嵌套的调用结构,直到找不到任何内网主机
而train部分就没有这个嵌套过程,不会对检测目标主机是否存在内网,和test不同的部分只是多了一些训练模型参数的代码。
train模式下,在通过execute_exploit验证模型给出的 “概率最大的payload” 的正确性之后(其余的payload都不考虑),会计算奖励,奖励的计算方法就是攻击成功,奖励值加一个固定值。通过 advantage_push_local_brain 去更新LocalBrain中的参数。
在Environment.run中,会把当前状态和可供选择的操作传过来
agent会让大脑(中的神经网络)给出对于状态s的预测值
1 | |
输出的结果p是一系列的概率,即针对available_action_list中的每一种payload 给出一个概率值,然后根据概率大小进行排序
1 | |
##### **`Agent.advantage_push_local_brain`**神经网络的输出的shape不是一个固定的值,它的长度取决于有多少种可供选择的action
将经验数据(包括状态、动作、奖励和下一个状态)推送到 LocalBrain 的训练队列中
首先使用 Bellman 方程来计算优势值
优势值表示了实际获得的奖励与预期奖励(由当前策略估计的价值函数)之间的差异。
然后将这些经验数据和优势值一起存储在 LocalBrain 的训练队列 train_queue 中。这个队列以批量的形式累积数据,直到达到一定的大小 MIN_BATCH。
当训练队列中的数据量达到 MIN_BATCH 或者在每个时间步后,LocalBrain 会从队列中取出数据,计算梯度,并更新其神经网络的参数。
class WorkerThread
这个类代表着一个训练线程或测试线程,由它去调用Environment.run,那里才是真正的强化学习执行代码
无论是train或test,都是一个死循环,靠isFinish这个全局变量控制循环的结束
在test中,只调用了一个Environment.run,(见 Environment.run),(生成报告的部分是train和test相同的),如下
1 | |
而train部分也只是比test部分多了一个画训练过程图的部分,不多做解释,重点也在Environment.run中。
三. 程序执行流程
解析命令行参数
1
rhost, mode, port, service = command_parse()根据rhost创建一个
Metasploit对象,对目标主机进行端口扫描见(Metasploit.get_port_list、Metasploit.execute_nmap)
1
2
3
4env = Metasploit(rhost)
...
env.execute_nmap(env.rhost, nmap_command, env.nmap_timeout)
com_port_list, proto_list, info_list = env.get_port_list(nmap_result, env.rhost)获取Metasploit的漏洞列表,存储在
data/exploit_list.csv中(见 Metasploit.get_exploit_list)1
com_exploit_list = env.get_exploit_list()获取Metasploit的payload列表,存储在
data/payload_list.csv中(见 Metasploit.get_payload_list)1
com_payload_list = env.get_payload_list()获取exploit_tree,这里面包含每个漏洞在不同操作系统下的不同payload(见 Metasploit.get_exploit_tree)
1
exploit_tree = env.get_exploit_tree()这步操作是在检查目标主机的服务和端口信息。
check_port_value函数是检查用户在客户端命令行参数输入的端口和服务是否合法(即检查port是不是0-65535,是否是前面nmap扫描到的端口之一),返回一个true/false。但实际上,更多的情况是由于没有指定端口和服务,从而产生的接下来的分支get_target_info:获取目标主机所有端口上的程序的信息(见Metasploit.get_target_info)最终结果包括有哪些服务,服务版本是什么,有哪些资源路径,有哪些漏洞可以攻击它。get_target_info_indicate:只分析指定的端口(见Metasploit.get_target_info_indicate)在这一步的实现中,Deep Exploit使用了两种方法对目标主机进行识别,一种是基于指纹的识别,一种是基于Naive Bayes算法的识别
1
2
3
4
5com_indicate_flag = check_port_value(port, service)
if com_indicate_flag:
target_tree, com_port_list = env.get_target_info_indicate(rhost, proto_list, info_list, port, service)
else:
target_tree = env.get_target_info(rhost, proto_list, info_list)准备训练/测试
从这里开始才体现出参数中的
train/test的作用,config.ini中定义了训练的线程数量是20,测试的线程数量是1。在ParameterServer中定义了强化学习的网络结构,见
ParameterServer._build_model1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20with tf.device("/cpu:0"):
parameter_server = ParameterServer()
threads = []
if mode == 'train':
# Create learning thread.
for idx in range(TRAIN_WORKERS):
thread_name = 'local_thread' + str(idx + 1)
threads.append(Worker_thread(thread_name=thread_name,
thread_type="learning",
parameter_server=parameter_server,
rhost=rhost))
else:
# Create testing thread.
for idx in range(TEST_WORKER):
thread_name = 'local_thread1'
threads.append(Worker_thread(thread_name=thread_name,
thread_type="test",
parameter_server=parameter_server,
rhost=rhost))训练/测试。模型参数会被保存在
trained_data目录下。训练和测试的具体过程见WorkerThread.run概括来说,用到的神经网络的功能就是:输入(操作系统类型、服务名、版本、可利用的漏洞、漏洞能够影响的操作系统版本),输出一串概率,对应每个可利用漏洞的成功概率。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21if mode == 'train':
# Load past learned data.
if os.path.exists(env.save_file) is True:
# Restore learned model from local file.
util.print_message(OK, 'Restore learned data.')
saver.restore(SESS, env.save_file)
# Execute learning.
for worker in threads:
job = lambda: worker.run(exploit_tree, target_tree, saver, env.save_file)
t = threading.Thread(target=job)
t.start()
else:
# Execute testing.
# Restore learned model from local file.
util.print_message(OK, 'Restore learned data.')
saver.restore(SESS, env.save_file)
for worker in threads:
job = lambda: worker.run(exploit_tree, target_tree)
t = threading.Thread(target=job)
t.start()