LLM学习笔记
Transformer
(复习一下transformer,忘干净了……)
整体上是一个encoder-decoder的结构
![]()
Encoder
由6个identical layer堆叠而成,identical layer包括一个multi-head attention层,一个feed forward层(全连接前馈网络position-wise fully connected feed-forward network),这两个子部分都做了残差(见下边大图)
Decoder
也是6个identical layer,包括三个子部分:一个masked multi-head attantion,一个multi-head attention,一个fee forward
![]()
自注意力机制
self-attention的self就是注意力的Query、Key、Value用的都是同一个矩阵(embedding之后的向量X)即 $X * W^{Q}=Q$,$XW^{K}=K$,$XW^{V}=V$
$Attention(Q,K,V)=softmax(QK^{T}/\sqrt{dk})V$
式子的含义为value的加权和,除以$\sqrt{dk}$是避免乘积过大,softmax是防止梯度太大
至于multi-head attention如何操作的,如下图所示
![]()
为什么叫多头呢?上面算的每一个Attention都叫做一个“头”,然后把他们们拼接在一起,然后乘一个矩阵(Linear)就得到了多头注意力。
那masked又是什么呢?(有没有mask体现在左图里的Mask(opt.)这里)在计算注意力权重时,对序列中未来的信息(即文本的后面部分)进行屏蔽,防止影响当前的输出,具体做法是,给后面的那些文本的注意力分数乘一个很大的负数,这样就忽略掉了他们的影响。
Position-wise前馈网络
$FFN(z)=max(0,zW_{1}+b_{1})W_{2}+b_{2}$
Positional encoding
这个东西在encoder-decoder最前面。模型不包含卷积和循环结构,但实际文本有需要有顺序特征,右侧decoder的输入是左侧的输入向右移一位的结果,positional encoding相当于在tokens之间引入了位置信息
$PE(pos,2i)=sin(pos/100000^{2i/d_{model}})$
$PE(pos,2i+1)=cos(pos/10000^{2i/d_{model}})$
整体结构
大部分博客帖子都只讲了encoder、decoder里边的东西,我一直不理解这6层encoder和decoder是如何连起来的,直到我找到了这张图( https://zhuanlan.zhihu.com/p/366014410 )。encoder的最后一层的输出作为6个decoder的multihead attention的K和V。
![]()
BERT
Bidirectional Encoder Representation from Transformers
CV里面早期就可以通过在大的数据集上(例如ImageNet)训练一个CNN,然后这个网络就可以用来在各种各样的下游任务上进行调整应用,但是NLP一直没有这样一个模型,都是各自训练各自的模型,BERT的出现弥补了NLP的这一点,(标题的Pre-training指的就是这个)
创新点有两个:
一个是用了mask,即对训练的句子盖住中间的某些内容,让模型去预测,这也符合这篇论文的名字“双向”的概念,让模型能够从两边都可以开始分析。(以前的GPT只用了单向,一个从左到右看句子的模型)
另一个是叫做“下一个句子的预测”(Next Sentence Prediction),即给两个句子判断他们在原文是不是相邻的,还是随机采样的两个句子
这篇文章基于两个工作:ELMO(也是双向的,但是用的是RNN的架构)、GPT(基于transformer,但只能单向),把他们合了起来,指出双向是一个非常有用的信息
训练
BERT的训练包括两部分,一部分是pre-training,在没有标签的数据集上训练,另一部分是fine-tuning,把前面预训练好的模型,在有标签的数据上训练所有模型参数参与训练
BERT训练时的输入是一个sequence,因为transformer在训练时要输入一对句子(encoder、decoder各一个),而BERT只有一个encoder,在处理两个句子的时候,直接并成一个序列。
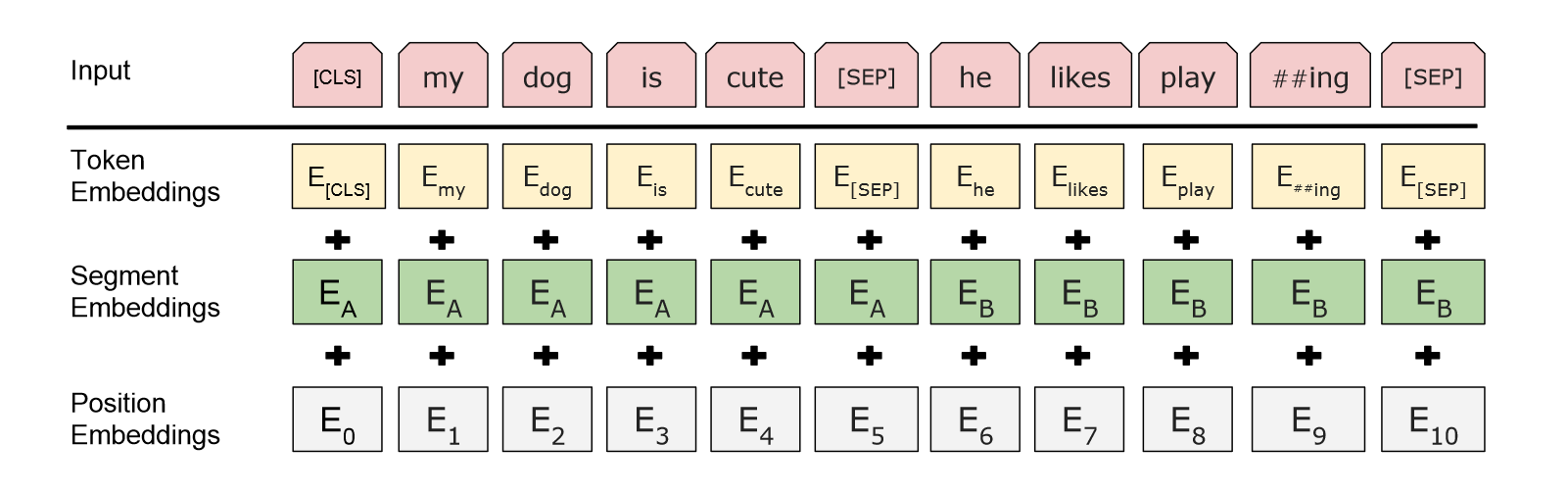
BERT用到了WordPiece来做embedding。和以前的直接以空格分词相比,WordPiece可以对于一些出现频率很小的单词,把他切开看他的一个子序列,这个子序列可能是一个词根,这个词根出现的概率比较大的话,只保留这个子序列。这个WordPiece的作用就是减小词典的大小。
输入的每个序列的开头都是一个$[CLS]$,希望最终的输出是表示整个序列的信息?为了区分拼在一起的两个句子,一方面是加一个$[SEP]$,另一方面加了一个embedding,用来区分是一个句子还是两个句子
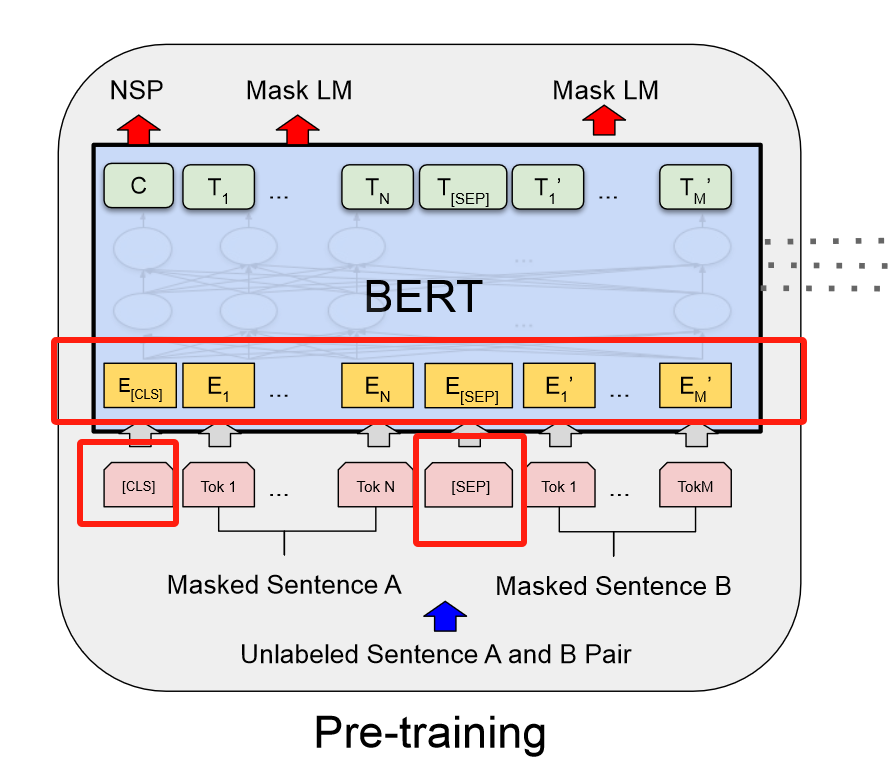
对于每一个token,进入bert的表示,是这个token的embedding,加上他在哪一个句子的embedding,加上位置的embedding
以上是bert在预训练和微调相同的部分
Pre-training
- Masked LM
对于除了$[CLS][SEP]$,其余的由WordPiece生成的token由15%的概率随即被替换成$[mask]$,但是在微调的时候不会有mask这一步,因此这里会产生一点问题,就是pre-training和fine-tuing时看到的训练数据不一样。
应对方法是,这15%的词,其中80%真的被替换成$[MASK]$,10%概率替换成一个随机的token,还有10%的概率什么都不改,但最后还是要预测这个词。(这个80%、10%、10%是怎么来的,在附录里做了ablation study)
- Next Sentence Prediction
拼起来的两个句子有50%的概率是在原文相邻的,50%概率是无关的
Fine-tuning
介绍了一下bert和transformer相比,只有encoder,同时处理两个序列
如果下游任务是一个句子分类(序列里只用一个句子),对$[CLS]$进行一个分类即可
实验
讲了bert在几个下游任务上的应用
Ablation Studies
证实了把模型堆的越来越大,效果会越来越好
还有把bert的输出不用来微调,而是作为一个特征输入进去,效果不会很好