菜鸡的2022datacon记录
固件基地址识别
rbasefind - https://github.com/sgayou/rbasefind
此项目用rust写的,用cargo build之后会生成可执行文件在target路径下
1 | |
1 | |
通常来讲第一行(也就是数字最大的那个)为固件的基地址,但是很多时候识别不出来(比如几行都是1)
实际在datacon的数据上测试的结果,使用的时候所有参数都是default(因为当时并没有仔细看代码….)

应该是50个固件识别成功了38个
对rbasefind源码的分析
按程序执行顺序分析
get_strings()利用一个正则表达式匹配
1
[ -~\t\r\n]{10,} // 从空格(48)到制表符(126) 以及 \r\n 的所有有效字符长度至少是10的字符串(10为参数minstrlen,最小字符串搜索长度)
get_pointers()提取整个文件的u32(?),会根据参数
big_endian判断文件的大小端find_match() -> Interval::get_range()把32位地址空间平均分为n部分,n位参数的threads(开启的线程数)
每一个interval对应一个线程,以offset字节为一组(offset为输入的参数,默认为4096)
下面的代码中current_addr遍历了
[interval.start_addr : interval.end_addr : offset]将每个str的首地址加上current_addr,把这些地址和pointers集合取交集
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17while current_addr <= interval.end_addr {
let mut news = FnvHashSet::default();
for s in strings {
match s.checked_add(current_addr) {
Some(add) => news.insert(add),
None => continue,
};
}
let intersection: FnvHashSet<_> = news.intersection(pointers).collect();
if !intersection.is_empty() {
heap.push((intersection.len(), current_addr));
}
match current_addr.checked_add(config.offset) {
Some(_) => current_addr += config.offset,
None => break,
};
}取出交集size最大的top n个current_addr进行输出
见本节最开头的示例,输出格式为 addr : interaction_size
size最大的即认为是最有可能的基地址
目前尚不清楚这样做的道理是什么
猜测:首先,基地址是一个offset的倍数,那么遍历0~2^32所有offset的倍数(也就是current_offset),字符串在程序运行时会被装载到基地址后面的一段空间内,而pointers里会有很多指向字符串真实地址的指针,如果能将strings和pointers匹配上很多,说明这个current_addr就是程序的基地址
(纯瞎猜💔)
函数符号恢复
几个已知的方法
我认为这篇文章写的很不错 https://blog.csdn.net/abel_big_xu/article/details/124388798
FLIRT
ida自带的一个插件,FLIRT可以对某个静态函数库生成签名,然后和待分析的程序匹配
缺点在于需要已知库函数文件
lscan
https://github.com/maroueneboubakri/lscan(我和前面挂着的那篇csdn文章作者一样,没搞懂这个工具)
lscan算是对flirt进行了一个包装,只要把一堆静态库放在一个文件夹里,他会遍历这个文件夹对每个静态库生成签名,然后再用FLIRT进行比对
lscan项目里自带的一些静态库是可以成功运行的,但是我试了一下写的静态库,例如sigdatabase https://github.com/push0ebp/sig-database 运行会报错
然后还有一个很奇怪的点在于匹配时对于某个库的相似度会超过百分之100%(在lscan的issue里也有人提到),但实际用ida的flirt打开时这个库并不能很好地匹配分析文件
Rizzo
没实际测试过,略
finger
finger是阿里云开发的ida插件 - https://github.com/aliyunav/Finger
用起来很简单
lumina
没有测试过,ida的一个官方符号识别插件,需要远程连接到ida lumina的服务器
有一个山寨版的服务器lumen,可以替代lumina,但好像现在已经不好使了
在datacon符号恢复数据集上的实测
给了20个程序,只有一个x86的程序,用finger基本能识别出来,有几个arm、mips的程序,还有其他很多奇奇怪怪的平台ida都反汇编不了,跟不用说符号恢复了,寄
powershell反混淆
PowerDecode - https://github.com/Malandrone/PowerDecode
对于单个文件反混淆很好用,而且实测比下边那个工具效果要好
但是问题在于,它提供的“分析整个文件夹下所有文件”功能,输出结果全是 1.txt 2.txt 3.txt …..
然后这些txt里也看不出来对应着哪个pwsh脚本,一开始想着是不是文件名称排列的顺序,但好像不对,代码全是powershell写的,也没搞懂该咋办
因此只能换了第二个工具
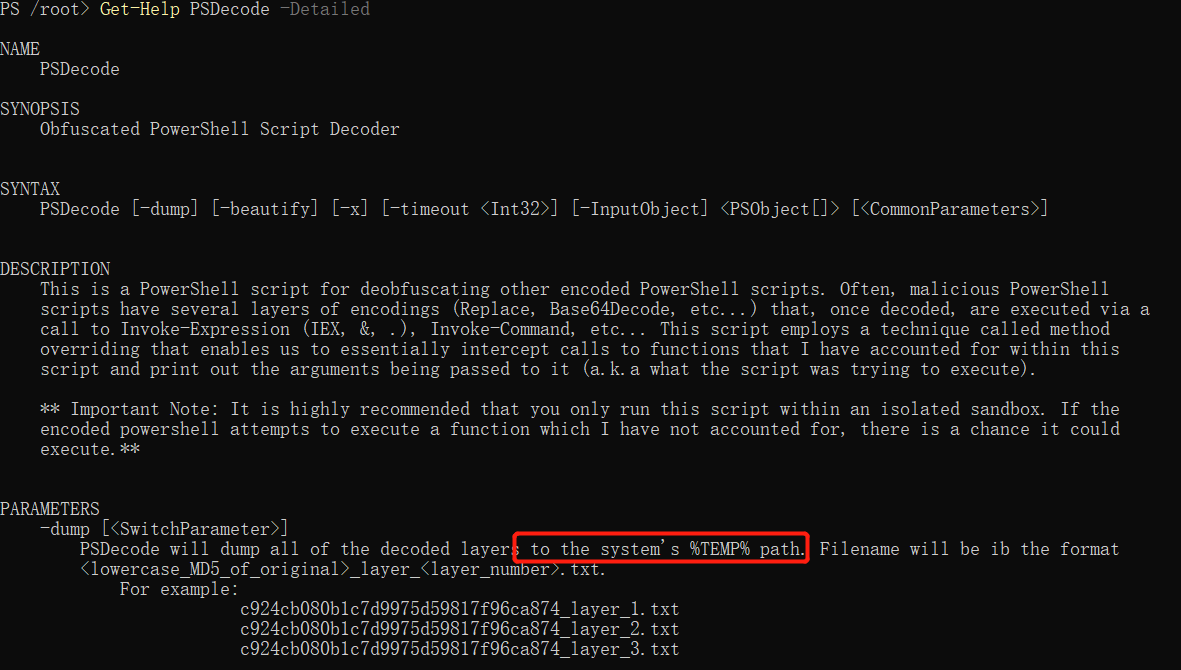
PSDecode - https://github.com/R3MRUM/PSDecode
会在TEMP路径下留下解析过程中各个layer的数据